
Seed-and-threshold segmentation
The process of segmentation refers to the selection of interesting features in a dataset and is a key step in the analysis of objects. Very much related to this is labeling, grouping together into a single entity (object) pixels that have something in common (typically, that they are adjacent in space). Huygens Object Analyzer includes various segmentation options, including AI-based segmentation.
Let us consider the one-dimensional case for the sake of simplicity, but this will also apply to a 3D image. Suppose that we have the following intensity distribution along one spatial coordinate (this could be e.g. the profile of one image's intensity along one line in space):

The simplest approach for segmenting features is to apply a threshold criterion: pixels having intensities above the threshold are considered to be interesting. Adjacent pixels can then be grouped together (labeled) forming a distinct object:
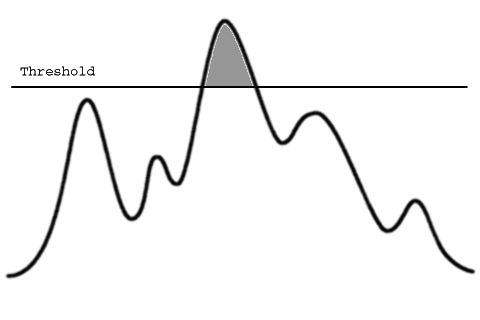
But in this case the selected object is too small. It may happen that we need to take larger objects for ulterior analysis. This can be achieved by lowering the threshold as follows:
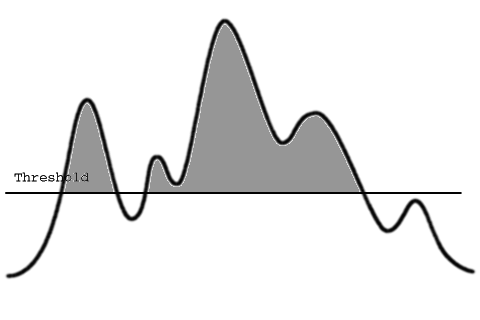
This second threshold defines two distinct objects: one big in the center (that has three peaks), and another one on the left (a single peak). Those two objects, defined with this threshold, are not spatially connected. (We can see that if we reduce the threshold a little bit more the selection will be expanded in such a way that the two regions will be connected, defining one single multi-peak object).
This can be a conflict in certain cases: we need a low threshold in order to take large, feature-rich objects, but lowering it too much will introduce undesired small objects in the selection.
One possible solution is to use a seed. You can see it as a secondary threshold. The first threshold selects the data and makes independent objects, but then only objects that go above the seed level remain, while the rest are discarded:
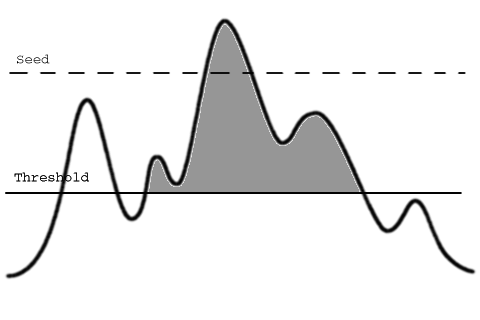
This level is called "seed" due to the way the segmentation is computed: the image is first explored for features that have intensities above the seed level, then the selection is expanded around this seed to capture all the neighbor VoXels down to the threshold.
By using this segmentation technique the Huygens Object Analyzer lets you find features in a more versatile way. To recover the simplest threshold behavior you just set the seed level equal to the threshold level (seed is 0 % above the threshold).
This VoXel selection is only one part of the feature finding problem. After the interesting voxels are defined, we still need to group them into distinct objects, and there are many possibilities for that. One robust criterion for 3D distributions like images from Fluorescence Microscopes is to label together adjacent voxels that share one face: they are said to be Six Connected. That is what the Object Analyzer does.
An additional segmentation technique that can be applied is the Watershed approach, and the selection of objects can be further refined using filtering criteria. This filtering can simply be based on size, by setting for example a Garbage Volume, or it can be based on more advanced object properties, such as whether they colocalize with objects in the other channel or not.