
Object segmentation
次の画像を撮ります。 あなたの脳は、すぐにその中のさまざまな存在を見つけます。
この識別は、これがアクチンフィラメントの画像であることをまだ知らなくても起こります。 明るい細長い構造とブラックホールが見えるのは、目と脳が協力してバックグラウンドから関心のある特徴を分離し、それらを分離しているためです。 明るいピクセルと暗いピクセルが表示されないだけで、明るいピクセルをグループ化してマクロ構造に属するようにします。
しかし、デジタル画像は、ある場所から別の場所へと変化する強度値の別々の集合にすぎず、ピクセルが対象物の一部なのか、バックグラウンドの一部なのかを判断できる固有の手順はありません。 私たちの脳は、これを行うのが速く、目自体で多くの前処理が行われます。 それらは、一緒に働くことについて非常に訓練されているので、洗練された方法で非常に類似した強度を分離し、何もないものを見ることさえできます!!! 同様の、またはさらに信頼できるデータ解釈をコンピュータで再現するにはどうすればよいでしょうか?
(実際には、バックグラウンドに対する対象物の観点から私たちが行う現実の解釈は、非常に単純化されており、形而上学的な困難にさらされています: 物質は、独立した分子と原子の集まりにすぎないため、物体は、正確にどこで終わり、他のすべては、どこで始まるのでしょうか? 実際には、いくつの物体が存在するのでしょうか? この問題は、蛍光顕微鏡の解像度をはるかに下回っていますが、物体が何であるかを定義するのは、簡単なことではないことを思い出させてくれます)。
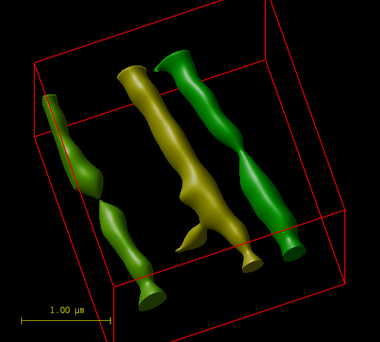
セグメンテーションの問題とは、画像の関心のある特徴を選択することです。 これに非常に関連するのは、ラベリングです、つまり、何か共通点がある(通常、空間で隣接している)ピクセルを単一の存在(対象物)にグループ化します。
これは、対象物のセグメンテーションの典型的なアプローチです:
- まず、実用的なアルゴリズムを使用して、関心のあるボクセルをバックグラウンドから分離します。 このアルゴリズムは、非常に複雑で洗練されたものにすることも、強度値に閾値を適用してボクセルを 2 つのグループ(対象とバックグラウンド)に分割するなど、単純で直感的なものにすることもできます。
- 関心のあるボクセルを分離したら、接続されている独立した対象物にグループ化します。 例えば、「それらが属する立方体の 1 つの面を共有する場合、接続されている」などの特定の手順が提供されます(これは、6 接続と呼ばれます)。 これを行うには、対象物ごとに異なるラベルを使用して、独立した対象物に属するすべてのボクセルに同じ数値ラベルを適用します。 これがラベリングと呼ばれる理由です。